Original Link: https://www.anandtech.com/show/1230
Intel's Pentium 4 E: Prescott Arrives with Luggage
by Anand Lal Shimpi & Derek Wilson on February 1, 2004 3:06 PM EST- Posted in
- CPUs
The Pentium 4 has come a long way since its introduction in the Fall of 2000. It went from being a laughable performer, to a CPU embraced by the community. Today Intel is extending the Pentium 4 family with the third major revision of the chip – codenamed Prescott.
Back when Prescott was nothing more than a curious block on Intel’s roadmap, we assumed that history would repeat itself: Intel would move to a smaller, 90nm process, double the cache and increase clock speeds. Intel has always historically behaved this way, they did so with the Pentium III and its iterations, and they did so with the first revisions of the Pentium 4. What we got with Prescott was much more than we bargained for.
Intel did move to a 90nm process, but at the same time didn’t produce a vastly cooler chip. Intel did double the cache, but also increased access latencies – a side effect we did not have with Northwood. Intel also moved to Prescott in order to increase clock speeds, however none of those speeds are available at launch (we’re still no faster than Northwood at 3.2GHz) and Intel did so at the expense of lengthening the pipeline; the Prescott’s basic Integer pipeline is now 31 stages long, up from the already lengthy 20 stages of Northwood. With Prescott, many more changes were made under the hood, including new instructions, some technology borrowed from the Pentium M and a number of algorithmic changes that affect how the CPU works internally.
If you thought that Prescott was just going to be smaller, faster, better – well, you were wrong. But at the same time, if you view it as longer, slower, worse – you’re not exactly on target either. Intel has deposited a nice mixed bag of technology on our doorsteps today, and it’s going to take a lot to figure out which side is up.
Let’s get to it.
Pipelining: 101
It seems like every time Intel releases a new processor we have to revisit the topic of pipelining to help explain why a 3GHz P4 performs like a 2GHz Athlon 64. With a 55% longer pipeline than Northwood, Prescott forces us to revisit this age old topic once again.
You've heard it countless times before: pipelining is to a CPU as the assembly line is to a car plant. A CPU's pipeline is not a physical pipe that data goes into and appears at the end of, instead it is a collection of "things to do" in order to execute instructions. Every instruction must go through the same steps, and we call these steps stages.
The stages of a pipeline do things like find out what instruction to execute next, find out what two numbers are going to be added together, find out where to store the result, perform the add, etc...
The most basic CPU pipeline can be divided into 5 stages:
1. Instruction Fetch
2. Decode Instructions
3. Fetch Operands
4. Execute
5. Store to Cache
You'll notice that those five stages are very general in their description, at the same time you could make a longer pipeline with more specific stages:
1. Instruction Fetch 1
2. Instruction Fetch 2
3. Decode 1
4. Decode 2
5. Fetch Operands
6. Dispatch
7. Schedule
8. Execute
9. Store to Cache 1
10. Store to Cache 2
Both pipelines have to accomplish the same task: instructions come in, results go out. The difference is that each of the five stages of the first pipeline must do more work than each of the ten stages of the second pipeline.
If all else were the same, you'd want a 5-stage pipeline like the first case, simply because it's easier to fill 5 stages with data than it is to fill 10. And if your pipeline is not constantly full of data, you're losing precious execution power - meaning your CPU isn't running as efficiently as it could.
The only reason you would want the second pipeline is if, by making each stage simpler, you can get the time it takes to complete each stage to be significantly quicker than in the previous design. Your slowest (most complicated) stage determines how quickly you can get data through each stage - keep that in mind.
Let's say that the first pipeline results in each stage taking 1ns to complete and if each stage takes 1 clock cycle to execute, we can build a 1GHz processor (1/1ns = 1GHz) using this pipeline. Now in order to make up for the fact that we have more stages (and thus have more of a difficult time keeping the pipeline full), the second design must have a significantly shorter clock period (the amount of time each stage takes to complete) in order to offer equal/greater performance to the first design. Thankfully, since we're doing less work per clock - we can reduce the clock period significantly. Assuming that we've done our design homework well, let's say we get the clock period down to 0.5ns for the second design.
Design 2 can now scale to 2GHz, twice the clock speed of the original CPU and we will get twice the performance - assuming we can keep the pipeline filled at all times. Reality sets in and it becomes clear that without some fancy footwork, we can't keep that pipeline full all the time - and all of the sudden our 2GHz CPU isn't performing twice as fast as our 1GHz part.
Make sense? Now let's relate this to the topic at hand.
31 Stages: What's this, Baskin Robbins?
Flip back a couple of years and remember the introduction of the Pentium 4 at 1.4 and 1.5GHz. Intel went from a 10-stage pipeline of the Pentium III to a 20-stage pipeline, an increase of 100%. Initially the Pentium 4 at 1.5GHz had a hard time even outperforming the Pentium III at 1GHz, and in some cases was significantly slower.
Fast forward to today and you wouldn't think twice about picking a Pentium 4 2.4C over a Pentium III 1GHz, but back then the decision was not so clear. Does this sound a lot like our CPU design example from before?
The 0.13-micron Northwood Pentium 4 core looked to have a frequency ceiling of around 3.6 - 3.8GHz without going beyond comfortable yield levels. A 90nm shrink, which is what we thought Prescott was originally going to be, would reduce power consumption and allow for even higher clock speeds - but apparently not high enough for Intel's desires.
Intel took the task of a 90nm shrink and complicated it tremendously by performing significant microarchitectural changes to Prescott - extending the basic integer pipeline to 31 stages. The full pipeline (for an integer instruction, fp instructions go through even more stages) will be even longer than 31 stages as that number does not include all of the initial decoding stages of the pipeline. Intel informed us that we should not assume that the initial decoding stages of Prescott (before the first of 31 stages) are identical to Northwood, the changes to the pipeline have been extensive.
The purpose of significantly lengthening the pipeline: to increase clock speed. A year ago at IDF Intel announced that Prescott would be scalable to the 4 - 5GHz range; apparently this massive lengthening of the pipeline was necessary to meet those targets.

Lengthening the pipeline does bring about significant challenges for Intel, because if all they did was lengthen the pipeline then Prescott would be significantly slower than Northwood on a clock for clock basis. Remember that it wasn't until Intel ramped the clock speed of the Pentium 4 up beyond 2.4GHz that it was finally a viable competitor to the shorter pipelined Athlon XP. This time around, Intel doesn't have the luxury of introducing a CPU that is outperformed by its predecessor - the Pentium 4 name would be tarnished once more if a 3.4GHz Prescott couldn't even outperform a 2.4GHz Northwood.
The next several pages will go through some of the architectural enhancements that Intel had to make in order to bring Prescott's performance up to par with Northwood at its introductory clock speed of 3.2GHz. Without these enhancements that we're about to talk about, Prescott would have spelled the end of the Pentium 4 for good.
One quick note about Intel's decision to extend the Pentium 4 pipeline - it isn't an easy thing to do. We're not saying it's the best decision, but obviously Intel's engineers felt so. Unlike GPUs that are generally designed using Hardware Description Languages (HDLs) using pre-designed logic gates and cells, CPUs like the Pentium 4 and Athlon 64 are largely designed by hand. This sort of hand-tuned design is why a Pentium 4, with far fewer pipeline stages, can run at multiple-GHz while a Radeon 9800 Pro is limited to a few hundred-MHz. It would be impossible to put the amount of design effort making a CPU takes into a GPU and still meet 6 month cycles.
What is the point of all of this? Despite the conspiracy theorist view on the topic, a 31-stage Prescott pipeline was a calculated move by Intel and not a last-minute resort. Whatever their underlying motives for the move, Prescott's design would have had to have been decided on at least 1 - 2 years ago in order to launch today (realistically around 3 years if you're talking about not rushing the design/testing/manufacturing process). The idea of "adding a few more stages" to the Pentium 4 pipeline at the last minute is not possible, simply because it isn't the number of stages that will allow you to reach a higher clock speed - but the fine hand tuning that must go into making sure that your slowest stage is as fast as possible. It's a long and drawn out process and both AMD and Intel are quite good at it, but it still takes a significant amount of time. Designing a CPU is much, much different than designing a GPU. This isn't to say that Intel made the right decision back then, it's just to say that Prescott wasn't a panicked move - it was a calculated one.
We'll let the benchmarks and future scalability decide whether it was a good move, but for now let's look at the mammoth task Intel brought upon themselves: making an already long pipeline even longer, and keeping it full.
Prescott's New Crystal Ball: Branch Predictor Improvements
We’ve said it before: before you can build a longer pipeline or add more execution units, you need a powerful branch predictor. The branch predictor (more specifically, its accuracy), will determine how many operations you can have working their way through the CPU until you hit a stall. Intel extended the basic Integer pipeline by 11 stages, so they need to make corresponding increases in the accuracy of Prescott’s branch predictor otherwise performance will inevitably tank.
Intel admits that the majority of the branch predictor unit remains unchanged in Prescott, but there have been some key modifications to help balance performance.
For those of you that aren’t familiar with the term, the role of a branch predictor in a processor is to predict the path code will take. If you’ve ever written code before, it boils down to being able to predict which part of a conditional statement (if-then, loops, etc…) will be taken. Present day branch predictors work on a simple principle; if branches were taken in the past, it is likely that they will be taken in the future. So the purpose of a branch predictor is to keep track of the code being executed on the CPU, and increment counters that keep track of how often branches at particular addresses were taken. Once enough data has accumulated in these counters, the branch predictor will then be able to predict branches as taken or not taken with relatively high accuracy, assuming they are given enough room to store all of this data.
One way of improving the accuracy of a branch predictor, as you may guess, is to give the unit more space to keep track of previously taken (or not taken) branches. AMD improved the accuracy of their branch predictor in the Opteron by increasing the amount of space available to store branch data, Intel has not chosen to do so with Prescott. Prescott’s Branch Target Buffer remains unchanged at 4K entries and it doesn’t look like Intel has increased the size of the Global History Counter either. Instead, Intel focused on tuning the efficiency of their branch predictor using less die-space-consuming methods.
Loops are very common in code, they are useful for zeroing data structures, printing characters or are simply a part of a larger algorithm. Although you may not think of them as branches, loops are inherently filled with branches – before you start a loop and every iteration of the loop, you must find out whether you should continue executing the loop. Luckily, these types of branches are relatively easy to predict; you could generally assume that if the outcome of a branch took you to an earlier point in the code (called a backwards branch), that you were dealing with a loop and the branch predictor should predict taken.
As you would expect, not all backwards branches should be taken – not all of them are at the end of a loop. Backwards branches that aren’t loop ending branches are sometimes the result of error handling in code, if an error is generated then you should back up and start over again. But if there’s no error generated in the application, then the prediction should be not-taken, but how do you specify this while keeping hardware simple?
Code Fragment A Line 10: while (i < 10) do |
Code Fragment B Line 10: A; |
|---|---|
| Line 14 is a backwards branch at the end of a loop - should be taken! | Line 80 is a backwards branch not at the end of a loop - should not be taken! |
It turns out that loop ending branches and these error branches, both backwards branches, differentiate themselves from one another by the amount of code that separates the branch from its target. Loops are generally small, and thus only a handful of instructions will separate the branch from its target; error handling branches generally instruct the CPU to go back many more lines of code. The depiction below should illustrate this a bit better:
Prescott includes a new algorithm that looks at how far the branch target is from the actual branch instruction, and better determines whether or not to take the branch. These enhancements are for static branch prediction, which looks at certain scenarios and always makes the same prediction when those scenarios occur. Prescott also includes improvements to its dynamic branch prediction.
Typical branches have one of two options: either don’t take the branch, or go to the target instruction and begin executing code there:
A Typical Branch ... |
|---|
There is a third type of branch – called an indirect branch – that complicates predictions a bit more. Instead of telling the CPU where to go if the branch is taken, an indirect branch will tell the CPU to look at an address in a register/main memory that will contain the location of the instruction that the CPU should branch to. An indirect branch predictor, originally introduced in the Pentium M (Banias), has been included in Prescott to predict these types of branches.
An Indirect Branch ... |
|---|
Conventionally, you predict an indirect branch somewhat haphazardly by telling the CPU to go to where most instructions of the program end up being located. It’s sort of like needing to ask your boss what he wants you to do, but instead of asking just walking into the computer lab because that’s where most of your work ends up being anyways. This method of indirect branch prediction ends up working well for a lot of cases, but not all. Prescott’s indirect branch predictor features algorithms to handle these cases, although the exact details of the algorithms are not publicly available. The fact that the Prescott team borrowed this idea from the Pentium M team is a further testament to the impressive amount of work that went into the Pentium M, and what continues to make it one of Intel’s best designed chips of all time.
Prescott’s indirect branch predictor is almost directly responsible for the 55% decrease in mispredicted branches in the 253.perlbmk SPEC CPU2000 test. Here’s what the test does:
253.perlbmk is a cut-down version of Perl v5.005_03, the popular scripting language. SPEC's version of Perl has had most of OS-specific features removed. In addition to the core Perl interpreter, several third-party modules are used: MD5 v1.7, MHonArc v2.3.3, IO-stringy v1.205, MailTools v1.11, TimeDate v1.08
The reference workload for 253.perlbmk consists of four scripts:
The primary component of the workload is the freeware email-to-HTML converter MHonArc. Email messages are generated from a set of random components and converted to HTML. In addition to MHonArc, which was lightly patched to avoid file I/O, this component also uses several standard modules from the CPAN (Comprehensive Perl Archive Network).
Another script (which also uses the mail generator for convienience) excercises a slightly-modified version of the 'specdiff' script, which is a part of the CPU2000 tool suite.
The third script finds perfect numbers using the standard iterative algorithm. Both native integers and the Math::BigInt module are used.
Finally, the fourth script tests only that the psuedo-random numbers are coming out in the expected order, and does not really contribute very much to the overall runtime.The training workload is similar, but not identical, to the reference workload. The test workload consists of the non-system-specific parts of the acutal Perl 5.005_03 test harness.
In the case of the mail-based benchmarks, a line with salient characteristics (number of header lines, number of body lines, etc) is output for each message generated.
During processing, MD5 hashes of the contents of output "files" (in memory) are computed and output.
For the perfect number finder, the operating mode (BigInt or native) is output, along with intermediate progress and, of course, the perfect numbers.
Output for the random number check is simply every 1000th random number generated.
As you can see, the performance improvement is in a real-world algorithm. As is commonplace for microprocessor designers to do, Intel measured the effectiveness of Prescott’s branch prediction enhancements in SPEC and came up with an overall reduction in mispredicted branches of about 13%:
| 164.gzip | 1.94% |
| 175.vpr | 8.33% |
| 176.gcc | 17.65% |
| 181.mcf | 9.63% |
| 186.crafty | 4.17% |
| 197.parser | 17.92% |
| 252.eon | 11.36% |
| 253.perlbmk | 54.84% |
| 254.gap | 27.27% |
| 255.vortex | -12.50% |
| 256.bzip2 | 5.88% |
| 300.twolf | 6.82% |
| Overall | 12.78% |
The improvements seen above aren’t bad at all, however remember that this sort of a reduction is necessary in order to make up for the fact that we’re now dealing with a 55% longer pipeline with Prescott.
The areas that received the largest improvement (> 10% fewer mispredicted branches) were in 176.gcc, 197.parser, 252.eon, 253.perlbmk and 254.gap. The 176.gcc test is a compiler test, which the Pentium 4 has clearly lagged behind the Athlon 64 in. 197.parser is a word processing test, also an area where the Pentium 4 has done poorly in the past thanks to branch-happy integer code. 252.eon is a ray tracer, and we already know about 253.perlbmk; improvements in 254.gap could have positive ramifications for Prescott’s performance in HPC applications as it simulates performance in math intensive distributed data computation.
The benefit of improvements under the hood like the branch prediction algorithms we’ve discussed here is that they are taken advantage of on present-day software, with no recompiling and no patches. Keep this in mind when we investigate performance later on.
We’ll close this section off with another interesting fact – although Prescott features a lot of new improvements, there are other improvements included in Prescott that were only introduced in later revisions of the Northwood core. Not all Northwood cores are created equal, but all of the enhancements present in the first Hyper Threading enabled Northwoods are also featured in Prescott.
An Impatient Prescott: Scheduler Improvements
Prescott can’t keep any more operations in flight (active in the pipeline) than Northwood, but because of the longer pipeline Prescott must work even harder to make sure that it is filled.
We just finished discussing branch predictors and their importance in determining how deep of a pipeline you can have, but another contributor to the equation is a CPU’s scheduling windows.
Let’s say you’ve got a program that is 3 operations long:
1. D = B + 1
2. A = 3 + D
3. C = A + B
You’ll notice that the 2nd operation can’t execute until the first one is complete, as it depends on the outcome (D) of the first operation. The same is true for the 3rd operation, it can’t execute until it knows what the value of A is. Now let’s say our CPU has 3 ALUs, and in theory could execute three adds simultaneously, if we just had this stream of operations going through the pipeline, we would only be using 1/3 of our total execution power - not the best situation. If we just upgraded from a CPU with 1 ALU, we would be getting the same throughput as our older CPU – and no one wants to hear that.
Luckily, no program is 3 operations long (even print “Hello World” is on the order of 100 operations) so our 3 ALUs should be able to stay busy, right? There is a unit in all modern day CPUs whose job it is to keep execution units, like ALUs, as busy as possible – as much of the time as possible. This is the job of the scheduler.
The scheduler looks at a number of operations being sent to the CPU’s execution cores and attempts to extract the maximum amount of parallelism possible from the operations. It does so by placing pending operations as soon as they make it to the scheduling stage(s) of the pipeline into a buffer or scheduling window. The size of the window determines the amount of parallelism that can be extracted, for example if our CPU’s scheduling window were only 3 operations large then using the above code example we would still only use 1/3 of our ALUs. If we could look at more operations, we could potentially find code that didn’t depend on the values of A, B or D and execute that in parallel while we’re waiting for other operations to complete. Make sense?
Because Intel increased the size of the pipeline on Prescott by such a large amount, the scheduling windows had to be increased a bit. Unfortunately, present microarchitecture design techniques do not allow for very large scheduling windows to be used on high clock speed CPUs – so the improvements here were minimal.
Intel increased the size of the scheduling windows used to buffer operations going to the FP units to coincide with the increase in pipeline.
There is also parallelism that can be extracted out of load and store operations (getting data out of and into memory). Let’s say that you have the following:
A = 1 + 3
Store A at memory location X
…
…
Load A from memory location X
The store operation actually happens as two operations (further pipelining by splitting up a store into two operations): a store address operation (where the data is going) and a store data operation (what the data actually is). The problem here is that the scheduler may try to parallelize the store operations and the load operation without realizing that the two are dependent on one another. Once this is discovered, the load will not execute and a performance penalty will be paid because the CPU’s scheduler just wasted time getting a load ready to execute and then having to get rid of it. The load will eventually execute after the store operations have completed, but at a significant performance penalty.
If a situation like the one mentioned above does crop up, long pipeline designs will suffer greatly – meaning that Prescott wants this to happen even less than Northwood. In Prescott, Intel included a small, very accurate, predictor to predict whether a load operation is likely to require data from a soon-to-be-executed store and hold that load until the store has executed. Although the predictor isn’t perfect, it will reduce bubbles of no-execution in the pipeline – a killer to Prescott and all long pipelined architectures.
Don’t look at these enhancements to improve performance, but to help balance the lengthened pipeline. A lot of the improvements we’ll talk about may sound wonderful but you must keep in mind that at this point, Prescott needs these technologies in order to equal the performance of Northwood so don’t get too excited. It’s an uphill battle that must be fought.
Execution Core Improvements
Intel lengthened the pipeline on Prescott but they did not give the CPU any new execution units; so basically the chip can run faster to crunch more data, but at the same speeds there are no enhancements to work any faster.
Despite the lack of any new execution units (this is nothing to complain about, remember the Athlon 64 has the same number of execution units as the Athlon XP), Intel did make two very important changes to the Prescott core that were made possible because of the move to 90nm.
Both of these changes can positively impact integer multiply operations; with one being a bit more positive than the other. Let us explain:
The Pentium 4 has three Arithmetic and Logic Units (ALUs) that handle integer code (code that operates on integer values - the vast majority of code you run on your PC). Two of these ALUs can crank out operations twice every clock cycle, and thus Intel marketing calls them "double pumped" and says that they operate at twice the CPU's clock speed. These ALUs are used for simple instructions that are easily executed within 1/2 of a clock cycle, this helps the Pentium 4 reach very high clock speeds (the doing less work per cycle principle).
More complicated instructions are sent to a separate ALU that runs at the core frequency, so that instead of complex instructions slowing down the entire CPU, the Pentium 4 can run at its high clock speeds without being bogged down by these complex instructions.
Before Prescott, one type of operation that would run on the slow ALU was a shift/rotate. One place where shifts are used is when multiplying by 2; if you want to multiply a number in binary by 2 you can simply shift the bits of the number to the left by 1 bit - the resulting value is the original number multiplied by 2.
In Prescott, a shift/rotate block has been added to one of the fast ALUs so that simple shifts/rotates may execute quickly.
The next improvement comes with actual integer multiplies; before Prescott, all integer multiplies were actually done on the floating point multiply unit and then sent back to the ALUs. Intel finally included a dedicated integer multiplier in Prescott, thanks to the ability to cram more 90nm transistors into a die size smaller than before. The inclusion of a dedicated integer multiplier is the cause of Prescott's "reduced integer multiply" claim.
Integer multiplies are quite common in all types of code, especially where array traversal is involved.
Larger, Slower Cache
On the surface Prescott is nothing more than a 90nm Pentium 4 with twice the cache size, but we’ve hopefully been able to illustrate quite the contrary thus far. Despite all of the finesse Intel has exhibited with improving branch predictors, scheduling algorithms and new execution blocks they did exploit one of the easiest known ways to keep a long pipeline full – increase cache size.
With Prescott Intel debuted their highest density cache ever – each SRAM cell (the building blocks of cache) is now 43% smaller than the cells used in Northwood. What this means is that Intel can pack more cache into an even smaller area than if they had just shrunk the die on Prescott.
While Intel has conventionally increased L2 cache size, L1 cache has normally remained unchanged – armed with Intel’s highest density cache ever, Prescott gets a larger L1 cache as well as a larger L2.
The L1 Data cache has been doubled to a 16KB cache that is now 8-way set associative. Intel states that the access latency to the L1 Data cache is approximately the same as Northwood’s 8KB 4-way set associative cache, but the hit rate (probability of finding the data you’re looking for in cache) has gone up tremendously. The increase in hit rate is not only due to the increase in cache size, but also the increase in associativity.
Intel would not reveal (even after much pestering) the L1 cache access latency, so we were forced to use two utilities - Cachemem and ScienceMark to help determine if there was any appreciable increase in access latency to data in the L1.
| Cachemem L1 Latency | ScienceMark L1 Latency | |
|---|---|---|
Northwood |
1 cycle |
2 cycles |
Prescott |
4 cycles |
4 cycles |
Although Cachemem and ScienceMark don't produce identical results, they both agree on one thing: Prescott's L1 cache latency is increased by more than an insignificant amount. We will just have to wait for Intel to reveal the actual access latencies for L1 in order to confirm our findings here.
Although the size of Prescott’s Trace Cache remains unchanged, the Trace Cache in Prescott has been changed for the better thanks to some additional die budget the designers had.
The role of the Trace Cache is similar to that of a L1 Instruction cache: as instructions are sent down the pipeline, they are cached in the Trace Cache while data they are operating on is cached in the L1 Data cache. A Trace Cache is superior to a conventional instruction cache in that it caches data further down in the pipeline, so if there is a mispredicted branch or another issue that causes execution to start over again you don’t have to start back at Stage 1 of the pipeline – rather Stage 7 for example.
The Trace Cache accomplishes this by not caching instructions as they are sent to the CPU, but the decoded micro operations (µops) that result after sending them through the P4’s decoders. The point of decoding instructions into µops is to reduce their complexity, once again an attempt to reduce the amount of work that has to be done at any given time to boost clock speeds (AMD does this too). By caching instructions after they’ve already been decoded, any pipeline restarts will pick up after the instructions have already made it through the decoding stages, which will save countless clock cycles in the long run. Although Prescott has an incredibly long pipeline, every stage you can shave off during execution, whether through Branch Prediction or use of the Trace Cache, helps.
The problem with a Trace Cache is that it is very expensive to implement; achieving a hit rate similar to that of an instruction cache requires significantly more die area. The original Pentium 4 and even today’s Prescott can only cache approximately 12K µops (with a hit rate equivalent to an 8 – 16KB instruction cache). AMD has a significant advantage over Intel in this regard as they have had a massive 64KB instruction cache ever since Athlon. Today’s compilers that are P4 optimized are aware of the very small Trace Cache so they produce code that works around it as best as possible, but it’s still a limitation.
Another limitation of the Trace Cache is that because space is limited, not all µops can be encoded within it. For example, complicated instructions that would take a significant amount of space to encode within the Trace Cache are instead left to be sequenced from slower ROM that is located on the chip. Encoding logic for more complicated instructions can occupy precious die space that is already limited because of the complexity of the Trace Cache itself. With Prescott, Intel has allowed the Trace Cache to encode a few more types of µops inside the Trace Cache – instead of forcing the processor to sequence them from microcode ROM (a much slower process).
If you recall back to the branch predictor section of this review we talked about Prescott’s indirect branch predictor – to go hand in hand with that improvement, µops that involve indirect calls can now be encoded in the Trace Cache. The Pentium 4 also has a software prefetch instruction that developers can use to instruct the processor to pull data into its cache before it appears in the normal execution. This prefetch instruction can now be encoded in the Trace Cache as well. Both of these Trace Cache enhancements are designed to reduce latencies as much as possible, once again, something that is necessary because of the incredible pipeline length of Prescott.
Finally we have Prescott’s L2 cache: a full 1MB cache. Prescott’s L2 cache has caught up with the Athlon 64 FX, which it needs as it has no on-die memory controller and thus needs larger caches to hide memory latencies as much as possible. Unfortunately, the larger cache comes at the sacrifice of access latency – it now takes longer to get to the data in Prescott’s cache than it did on Northwood.
| Cachemem L2 Latency | ScienceMark L2 Latency | |
|---|---|---|
Northwood |
16 cycles |
16 cycles |
Prescott |
23 cycles |
23 cycles |
Both Cachemem and ScienceMark agree on Prescott having a ~23 cycle L2 cache - a 44% increase in access latency over Northwood. The only way for Prescott's slower L2 cache to overcome this increase in latency is by running at higher clock speeds than Northwood.
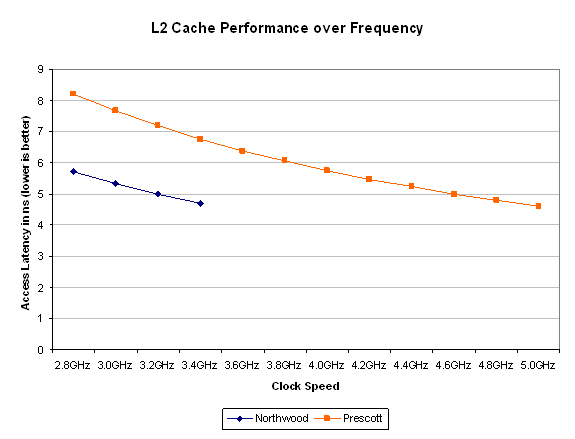
If our cache latency figures are correct, it will take a 4GHz Prescott to have a faster L2 cache than a 2.8GHz Northwood. It will take a 5GHz Prescott to match the latency of a 3.4GHz Northwood. Hopefully by then the added L2 cache size will be more useful as programs get larger, so we'd estimate that the Prescott's cache would begin to show an advantage around 4GHz.
Intel hasn’t changed any of the caching algorithms or the associativity of the L2 cache, so there are no tricks to reduce latency here – Prescott just has to pay the penalty.
For today’s applications, this increase in latency almost single handedly eats away any performance benefits that would be seen by the doubling of Prescott’s cache size. In the long run, as applications and the data they work on gets larger the cache size will begin to overshadow the increase in latency, but for now the L2 latency will do a good job of keeping Northwood faster than Prescott.
Thirteen New Instructions - SSE3
Back at IDF we learned about the thirteen new instructions that Prescott would bring to the world; although they were only referred to as the Prescott New Instructions (PNI) back then, it wasn't tough to guess that their marketing name would be SSE3.
The new instructions are as follows:
FISTTP, ADDSUBPS, ADDSUBPD, MOVSLDUP, MOVSHDUP, MOVDDUP, LDDQU, HADDPS, HSUBPS, HADDPD, HSUBPD, MONITOR, MWAIT
The instructions can be grouped into the following categories:
x87 to integer conversion
Complex arithmetic
Video Encoding
Graphics
Thread synchronization
You have to keep in mind that unlike the other Prescott enhancements we've mentioned today, these instructions do require updated software to take advantage of. Applications will either have to be recompiled or patched with these instructions in mind. With that said, let's get to highlighting what some of these instructions do.
The FISTTP instruction is useful in x87 floating point to integer conversion, which is an instruction that will be used by applications that are not using SSE for their floating point math.
The ADDSUBPS, ADDSUBPD, MOVSLDUP, MOVSHDUP and MOVDDUP instructions are all grouped into the realm of "complex arithmetic" instructions. These instructions are mostly designed to reduce latencies in carrying out some of these complex arithmetic instructions. One example are the move instructions, which are useful in loading a value into a register and adding it to other registers. The remaining complex arithmetic instructions are particularly useful in Fourier Transforms and convolution operations - particularly common in any sort of signal processing (e.g. audio editing) or heavy frequency calculations (e.g. voice recognition).
The LDDQU instruction is one Intel is particularly proud of as it helps accelerate video encoding and it is implemented in the DivX 5.1.1 codec. More information on how it is used can be found in Intel's developer documentation here.
In response to developer requests Intel has included the following instructions for 3D programs (e.g. games): haddps, hsubps, haddpd, hsubpd. Intel told us that developers are more than happy with these instructions, but just to make sure we asked our good friend Tim Sweeney - Founder and Lead Developer of Epic Games Inc (the creators of Unreal, Unreal Tournament, Unreal Tournament 2003 and 2004). Here's what he had to say:
Most 3D programmers been requesting a dot product instruction (similar to the shader assembly language dp4 instruction) ever since the first SSE spec was sent around, and the HADDP is piece of a dot product operation: a pmul followed by two haddp's is a dot product.
This isn't exactly the instruction developers have been asking for, but it allows for performing a dot product in fewer instructions than was possible in the previous SSE versions. Intel's approach with HADDP and most of SSE in general is more rigorous than the shader assembly language instructions. For example, HADDP is precisely defined relative to the IEEE 754 floating-point spec, whereas dp4 leaves undefined the order of addition and the rounding points of the components additions, so different hardware implementing dp4 might return different results for the same operation, whereas that can't happen with HADDP.
As far as where these instructions are used, Tim had the following to say:
Dot products are a fundamental operation in any sort of 3D programming scenario, such as BSP traversal, view frustum tests, etc. So it's going to be a measurable performance component of any CPU algorithm doing scene traversal, collision detection, etc.
The HSUBP ops are just HADDP ops with the second argument's sign reversed (sign-reversal is a free operation on floating-point values). It's natural to support a subtract operation wherever one supports an add.
So the instructions are useful and will lead to performance improvements in games that do take advantage of them down the road. The instructions aren't everything developers have wanted, but it's good to see that Intel is paying attention to the game development community, which is something they have done a poor job of doing in the past.
Finally we have the two thread synchronization instructions - monitor and mwait. These two instructions work hand in hand to improve Hyper Threading performance. The instructions work by determining whether a thread being sent to the core is the OS' idle thread or other non-productive threads generated by device drivers and then instructing the core to worry about those threads after working on whatever more useful thread it is working on at the time. Unfortunately monitor and mwait will both require OS support to be used, meaning that we will either be waiting for Longhorn or the next Service Pack of Windows for these two instructions.
Intel would not confirm whether the instructions can be used in a simple service pack update; they simply indicated that they were working with Microsoft of including support for them. We'd assume that they would be a bit more excited about the ability to bring the instructions to Prescott users via a simple service pack update, maybe indicating that we will have to wait for the next version of Windows before seeing these two in use.
Half-Time Summary
At this point we’re done with talking about all of the microarchitectural changes that have gone into Prescott. We know it’s a lot of information so let’s go through a brief rundown of what we’ve learned so far:
- Prescott’s 31 stage pipeline by itself makes the processor significantly slower than Northwood on a clock for clock basis.
- Prescott’s L2 cache, albeit larger than Northwoods, has a higher access latency – also resulting in lower performance for the 90nm chip
- Through improvements in branch predicting, scheduling algorithms and integer execution, Intel has managed to hide a lot of the downsides to extending the pipeline.
- The large L2 cache also helps keep the pipeline full.
- SSE3 instructions will be useful down the road, but the impact given today’s software will be negligible.
- Extending the pipeline to 31 stages will allow Prescott to scale to speeds in the 4 – 5GHz range next year. It will take those speeds to make Prescott a true successor to Northwood.
With that said, let’s look at more of the common areas of discussion about the new chip.
Something to be proud about
Intel is particularly proud of their 90nm process as it incorporates new technologies that are a first in desktop microprocessors. The biggest of them all is the use of Strained Silicon, which we explained back in August of 2002 when Intel first announced that they would use the technology:
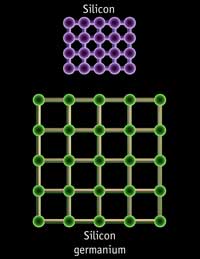
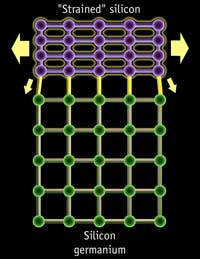
Strained Silicon works by effectively stretching the silicon in the channel region of the transistor. The engineers at Intel's fab facilities don't sit there and pull on both ends of the silicon in order to get it to stretch; rather they place the silicon on top of a substrate whose atoms are already spaced further apart than the silicon that needs to be stretched. The result of this is that the silicon atoms on top of the substrate will stretch to match the spacing of the substrate below, thus "stretching" the silicon in the channel.
 |
 |
|
Silicon is "strained" by using a substrate of more widely spaced atoms below the silicon channel of a transistor. (Images courtesy of IBM) |
|
With more well spaced silicon atoms, electrons can now flow with less resistance in the channel meaning that more current can flow through the channel when needed. The end result is a 10 - 20% increase in drive current, or the current flowing through the channel of the transistor.
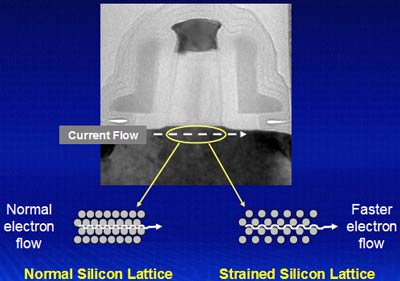
Intel claims that their Strained Silicon technology has no real downsides (unlike competing solutions) other than its 2% increase in manufacturing costs. Intel's 90nm process will make use of Strained Silicon technology to improve the performance of their 90nm transistors.
Intel’s 90nm process does not make use of Silicon on Insulator and according to their manufacturing roadmaps it never will. Intel will introduce SOI on their 65nm process in 2005.

Prescott's 112 mm^2 die
Prescott is Intel’s first desktop microprocessor to have 7 metal layers, 2 fewer layers than AMD’s Athlon 64. Intel had to add the 7th layer simply because of the skyrocketing transistor count of Prescott (125 million vs. Northwood’s 55 million). It’s not normally desirable to increase the number of metal layers you have on a chip as it increases manufacturing complexity and cost, but in some cases it is unavoidable. The fact that Intel was able to keep the number of metal layers down to 7 is quite impressive, as AMD had to resort to 9 layers dating back to the introduction of their Thoroughbred-B Athlon XP core to keep clock speeds high.
|
CPU Core Comparison |
|||||
| Code Name |
Willamette |
Northwood |
Northwood EE |
Prescott |
AMD Athlon 64 |
| Manufacturing Process |
0.18-micron |
0.13-micron |
0.13-micron |
90 nm |
0.13-micron |
| Die Size |
217 mm^2 |
131 mm^2 |
237 mm^2 |
112 mm^2 |
193 mm^2 |
| Metal Layers |
6 |
6 |
6 |
7 |
9 |
| Transistor Count |
42 Million |
55 Million |
178 Million |
125 Million |
105.9 Million |
| Voltage |
1.750V |
1.50V |
1.50V |
1.385V |
1.50V |
| Clock Speeds |
1.3 - 2.0GHz |
1.6 - 3.4GHz |
3.2 - 3.4GHz |
2.8 - 4GHz+ |
2.0GHz+ |
| L1 Instruction/Trace Cache | 12K µops |
12K µops |
12K µops |
12K µops |
64KB |
| L1 Data Cache | 8KB |
8KB |
8KB |
16KB |
64KB |
| L2 Cache | 256KB |
512KB |
512KB |
1MB |
1MB |
| L3 Cache | N/A |
N/A |
2MB |
N/A |
N/A |
So, what’s being launched today?
Intel has dropped one hell of a package on our doorsteps today and we’ve made it through all of the architecture, but can we make sense of their marketing? We kid, we kid, it’s not all that bad.
Intel wants to shift all Pentium 4s over to Prescott as soon as possible, mostly because once production ramps up it will be cheaper for Intel to make a 112 mm^2 Prescott than it is for them to make a 131 mm^2 Northwood. Therefore Prescott launches at clock speeds that are equivalent to currently available Northwoods.
In Intel’s usual style, if there are two different cores with the same clock speed Intel will use a single letter to differentiate them. In the case of Prescott the magic letter is ‘E’, so all ‘E’ processors will mean they are Prescott based.
Prescott is being launched today at four clock speeds, giving us the following:
Pentium 4 3.40E
Pentium 4 3.20E
Pentium 4 3.00E
Pentium 4 2.80E
But don’t get too excited, the 3.40E chip isn’t actually available yet and to make up for that fact Intel also released a Northwood based 3.40GHz Pentium 4. The Northwood based Pentium 4 3.40GHz is currently available, but within the coming months you’ll see them replaced with Prescott based 3.40Es.
In an interesting move by Intel, Northwoods and Prescotts at the same clock speed will be priced identically. Intel is hoping that the price parity will make people choose Prescott over Northwood (why not? You get twice as much cache for free!) but this policy also works in our favor. In order for most vendors to get rid of Northwood inventory you can expect prices to be cheaper than Prescotts.
With a BIOS update these ‘E’ CPUs will work on currently 875/865 motherboards, but check with your motherboard manufacturer first to make sure. We will have a motherboard compatibility article out as soon as possible to document any combinations you should stay away from.
Today Intel is also introducing the Pentium 4 Extreme Edition running at 3.4GHz. This EE is based on the same 0.13-micron process as its predecessor; although there are currently no plans for a 90nm Extreme Edition you can expect one to appear once Prescott begins to approach Extreme Edition performance.
Availability, Yields and Overclocking
Intel’s 90nm fabs are working hard at cranking out Prescotts as fast as possible, but as is the case at the start of any ramp there will be supply issues. We are hearing that widespread availability of chips in the channel for people like us to order won’t be until March 1st, although you should be able to find OEMs with systems available immediately.
We are also hearing from reliable sources that the current steppings of Prescotts coming out of the fabs are performing very well. To get an idea for what sort of headroom to expect we conducted some informal overclocking tests on our Pentium 4 3.20E that we had for testing.
We conducted all tests using just air cooling and we kept the CPU voltage at its default of 1.385V:
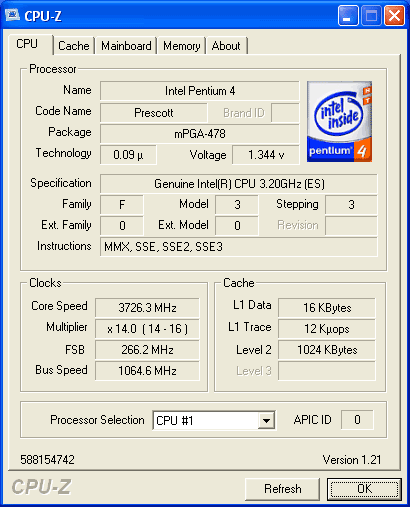
An effortless overclock gave us 3.72GHz; we could POST at 4GHz but we didn’t want to showcase what was ultimately possible with Prescott, rather what was easily attainable without increasing voltages.
Intel could have launched Prescott at higher clock speeds than they did, however it seems that their desire to produce as many mainstream Prescotts as possible (2.80E in particular) won out in this case.
Update: Intel has released the official thermal data on Prescott:
| Thermal Design Power | |
|---|---|
Northwood (2.8 - 3.4GHz) |
69 - 89W |
Prescott (2.8 - 3.4GHz) |
89 - 103W |
As we mentioned before, if you thought Prescott was going to be cooler running you'd be wrong. Prescott is one hot running CPU, now keep in mind that these aren't actual production thermals rather Intel's guidelines to manufacturers as to what thermals they should design cooling for. Needless to say, Prescott at 2.8GHz will be about as hot as a 3.4GHz Northwood. When Intel ramps up beyond 3.6GHz we'll definitely see some larger heatsinks being used on Pentium 4 platforms; some of the preliminary cooling setups we've seen for Tejas were insane.
Prescott's 2004 Ramp
We've published a full article on Intel's 2004 CPU Roadmap but here's a quick look at where Prescott is headed this year:
| 2004 LGA-775 Pentium 4 Roadmap | ||||
|---|---|---|---|---|
| CPU | Manufacturing Process |
Bus Speed |
L2 Cache Size |
Release Date |
| Pentium 4 4.0GHz | 90nm |
800MHz |
1MB |
Q4 '04 |
| Pentium 4 3.8GHz | 90nm |
800MHz |
1MB |
Q3 '04 |
| Pentium 4 3.6GHz | 90nm |
800MHz |
1MB |
Q2 '04 |
| Pentium 4 3.4GHz | 90nm |
800MHz |
1MB |
Q2 '04 |
| Pentium 4 3.2GHz | 90nm |
800MHz |
1MB |
Q2 '04 |
| Pentium 4 3.0GHz | 90nm |
800MHz |
1MB |
Q2 '04 |
| Pentium 4 2.8GHz | 90nm |
800MHz |
1MB |
Q2 '04 |
The Test
| Performance Test Configuration | |
| Processor(s): | AMD Athlon 64 3000+ AMD Athlon 64 3200+ AMD Athlon 64 3400+ AMD Athlon 64 FX51 Intel Pentium 4 3.2GHz EE Intel Pentium 4 3.4GHz EE Intel Pentium 4 3.2GHz Intel Pentium 4 3.0GHz Intel Pentium 4 2.8GHz Intel Pentium 4 3.2EGHz Intel Pentium 4 3.0EGHz Intel Pentium 4 2.8EGHz |
| RAM: | 2 x 512Mb OCZ 3500 Platinum Ltd 2 x 512Mb Mushkin ECC Registered High Performance 2:3:2 |
| Hard Drive(s): | Seagate 120GB 7200 RPM (8MB Buffer) |
| Video AGP & IDE Bus Master Drivers: | VIA Hyperion 4.51 (12/02/03) Intel Chipset Drivers |
| Video Card(s): | Sapphire ATI Radeon 9800 PRO 128MB (AGP 8X) |
| Video Drivers: | ATI Catalyst 4.10 |
| Operating System(s): | Windows XP Professional SP1 |
| Motherboards: | Intel D875PBZ (Intel 875P Chipset) FIC K8-800T (VIA K8T800 Chipset) ASUS SK8V (VIA K8T800 Chipset) |
Business Winstone 2004
With our very first look at Prescott performance, we see that despite the long pipeline, cache latencies and other performance impacting attributes, Intel has managed to do a good job of keeping performance of their new flagship processor right on par with Northwood in a very important catagory: business productivity software.
This might not be the benchmark most enthusiasts are looking for, but it is very important for Intel. Corporate customers are a big part of the game when it comes to selling desktop parts, and, with more and more companies realizing that AMD is out there, not slipping in performance here is very positive for Intel
SYSmark 2004 Overall
The entire sysmark run including all the individual tests we will be reporting took anwhere between two and three hours to run. The two main suites (Internet Content Creation and Office Productivity) each took up half of the time (in contrast to Winstone where the business benchmark completes much faster than content creation).
The overall score which takes a little of everything into account shows the Gallatin based Extreme Edition coming out on top in both of its flavors followed by the fastest Prescott.
This is the first time we've run Sysmark in our labs, and we weren't sure what to expect from this highly visible test suite. We can say that the numbers we see here an in the following graphs don't tend to reflect what we see though out the rest of our testing.
We included these numbers for completions' sake but we are not going to draw any conclusions based on the benchmark as we have not had much experience with it. We do know that this time around AMD did have equal input into the creation of the benchmark, although it does still seem to favor Intel's architectures.
DirectX 9 Performance
Aquamark
We can see that the actual game performance doesn't vary much over these high end processors. However, when we look at the seperate CPU score for each processor, we can see that the Intel line of proceossors tend to do a bit more behind the scenes than AMDs. Prescott laggs behind Northwood in this benchmark as well.
DirectX 8 Performance
Unreal Tournament
The high end Athlons are able to keep the Pentium 4 EE CPUs at bay in Unreal. It is also apparent that there is some increasing difference between Northwood and Prescott in this Benchmark.
OpenGL Performance
Quake III Arena
This benchmark was run with all the settings on high quality at 1024x768 using vertex lighting rather than lightmapping. We can see that the large cache of the EE processors is a huge benefit here allowing them to post huge numbers. Only the fastest Prescott is able to best its equivalently clocked rival.
DIVX 5.1.1 Encoding
This is another benchmark in which the large cache of the EE really helps out. Prescott does a good job of keeping up with the Northwood processors here, and as usualy, Intel's line of processors outperform AMDs when it comes to encoding. Also remember that the DivX 5.1.1 codec has support for the SSE3 instruction LDDQU, which makes the performance below a bit perplexing:
3D Rendering Performance
3dsmax R5
Development Workstation Performance
The AMD line of processors are in no danger of loosing their advantage when it comes to software compilation. Even with its improvements to its branch predictor, the increased cache latency and longer pipeline take a hard hit in this benchmark.
Prescott's Little Secret
In learning about Prescott and trying to understand just why Intel did what they did, we came to realization: not only is Prescott designed to be ramped in speed, but there was something else hiding under the surface.
When overclocking a processor, we can expect a kind of linear trend in performance. As Northwood's speed increases, its performance increases. The same is true for Prescott , but what is important to look at is increase in performance compared to increase in clock speed.
Prescott 's enhancements actually give it a steeper increase in performance per increase in clock. Not only can Prescott be clocked higher than Northwood, but as its clock speed is increased, it will start to outperform similarly clocked Northwood CPUs.
We can even see this trend apparent in our limited 3 clock speed tests. Most of the time, the 2.8GHz Northwood outperforms the 2.8GHz Prescott, but the percentage by which Prescott is outperformed decreases as clock speed increases, meaning that the performance delta is significantly less at 3.2GHz.
Business Winstone 2004
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
1.48% |
3.00GHz |
0.00% |
3.20GHz |
0.46% |
Content Creation Winstone 2004
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-3.57% |
3.00GHz |
-5.67% |
3.20GHz |
-5.43% |
SYSMark 2004
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
1.19% |
3.00GHz |
2.27% |
3.20GHz |
2.70% |
SYSMark was one of the only applications to show a positive performance improvement for Prescott, and we see that with clock speed that advantage continues to grow over Northwood. Keep on reading, it gets even more interesting...
Aquamark - CPU Score
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-2.87% |
3.00GHz |
-2.47% |
3.20GHz |
-0.84% |
Halo
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-0.18% |
3.00GHz |
-0.18% |
3.20GHz |
0.00% |
GunMetal
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-0.29% |
3.00GHz |
-0.58% |
3.20GHz |
-0.29% |
UT2003 - Flyby
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-2.62% |
3.00GHz |
-1.46% |
3.20GHz |
-0.86% |
Clock speed goes up, Prescott performs more like Northwood.
UT2003 - Botmatch
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-3.55% |
3.00GHz |
-3.09% |
3.20GHz |
-2.05% |
Warcraft 3
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
1.96% |
3.00GHz |
1.12% |
3.20GHz |
0.72% |
We continue to see that as clock speed increases, the gap between Prescott and Northwood decreases as well.
Quake III Arena
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-1.33% |
3.00GHz |
-0.49% |
3.20GHz |
1.28% |
Quake becomes the textbook case of what should happen to Prescott performance as clock speed increases; although initially it is slightly slower than Northwood at 2.80GHz, by the time we reach 3.2GHz Prescott holds an advantage over a 3.2GHz Northwood. This is exactly the trend we expect to see over time, especially once we get close to 4GHz.
Jedi Knight: Jedi Academy
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-7.63% |
3.00GHz |
-6.85% |
3.20GHz |
-7.04% |
Wolfeinstein: Enemy Territory
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-5.53% |
3.00GHz |
-4.94% |
3.20GHz |
-3.79% |
DivX Encoding
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-1.30% |
3.00GHz |
-0.61% |
3.20GHz |
-0.38% |
3dsmax R5
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-9% |
3.00GHz |
|
3.20GHz |
-9% |
There will be some scenarios that do not work in Prescott's favor, and in those cases Northwood will still remain faster.
Lightwave 7.5
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-7.7% |
3.00GHz |
|
3.20GHz |
-6.8% |
Although to a much lesser degree, we are seeing the same sort of scaling with clock speed in applications like Lightwave. It looks like our theory about Prescott's performance is correct.
Visual Studio Compile Test
| Percentage Increase in Performance from Northwood to Prescott | |
|---|---|
2.80GHz |
-8.2% |
3.00GHz |
|
3.20GHz |
-3.8% |
Much like Quake, our compile test is another perfect example of what clock scaling will do to the Northwood/Prescott gap. As the clock speed goes up, the performance delta decreases.
Final Words
If you’re looking for nothing more than a purchasing decision let’s put it simply: if you’re not an overclocker, do not buy any Prescott where there is an equivalently clocked Northwood available. This means that the 2.80E, 3.00E, 3.20E are all off-limits, you will end up with a CPU that is no faster than a Northwood and in most cases slower. If you are buying a Pentium 4 today, take advantage of the fact that vendors will want to get rid of their Northwood based parts and grab one of them.
Overclockers may want to pick up a Prescott to experiment with ~4GHz overclocks – it will be easier on Prescott than it is on Northwood. And once you get beyond currently available Northwood speeds you will have a CPU that is just as fast if not faster, depending on how high you go.
When you include AMD in the picture, the recommendation hasn’t changed since the Athlon 64 was introduced. If you find yourself using Microsoft Office for most of your tasks and if you’re a gamer the decision is clear: the Athlon 64 is for you. The Pentium 4 continues to hold advantages in content creation applications, 3D rendering and media encoding; if we just described how you use your computer then the Pentium 4 is for you, but the stipulation about Northwood vs. Prescott from above still applies.
The Pentium 4 Extreme Edition at 3.4GHz does provide an impressive show, but at a street price of over $1100 it is tough recommending it to anyone other than Gates himself.
With the recommendations out of the way, now let’s look at Prescott from a purely microarchitectural perspective.
Given that we’re at the very beginning of the 90nm ramp and we are already within reach of 4GHz, it isn’t too far fetched that Prescott will reach 5GHz if necessary next year. From an architecture perspective, it is impressive that Prescott remains in the same performance league as Northwood despite the fact that it has a 55% longer pipeline.
What we have seen here today does not bode well for the forthcoming Prescott based Celerons. With a 31 stage pipeline and 1/4 the cache size of the P4 Prescott, it doesn’t look like Intel will be able to improve Celeron performance anytime soon. We will keep a close eye on the value segment as it is an area where AMD could stand to take serious control of the market.
The performance of Prescott today is nothing to write home about, and given the extensive lengthening of the pipeline it’s honestly a surprise that we’re not castrating Intel for performance at this point. Prescott is however a promise of performance to come; much like the Willamette and even Northwood cores were relatively unimpressive at first, they blossomed into much sought-after CPUs like the Pentium 4 2.4C. The move to 90nm and a longer pipeline will undoubtedly mean more fun for the overclocking community, especially once production ramps up on Prescott.
Just as was the case with the very first Pentium 4s, Prescott needs higher clock speeds to spread its wings - our data on the previous page begins to confirm this. To put it bluntly: Prescott becomes interesting after 3.6GHz; in other words, after it has completely left Northwood’s clock speeds behind.






